Why a feedback loop is the quiet engine of product ops
A resilient product operations feedback loop keeps your roadmap tethered to real customer needs. Without it, teams ship in the dark and chase noise. With it, you get a continuous line from signal to decision to outcome.
The goal is simple: capture, process, and act on feedback with discipline. Not once, but every week. This article breaks down how we build a feedback river that flows through product ops, turns into clear decisions, and closes the loop with customers.
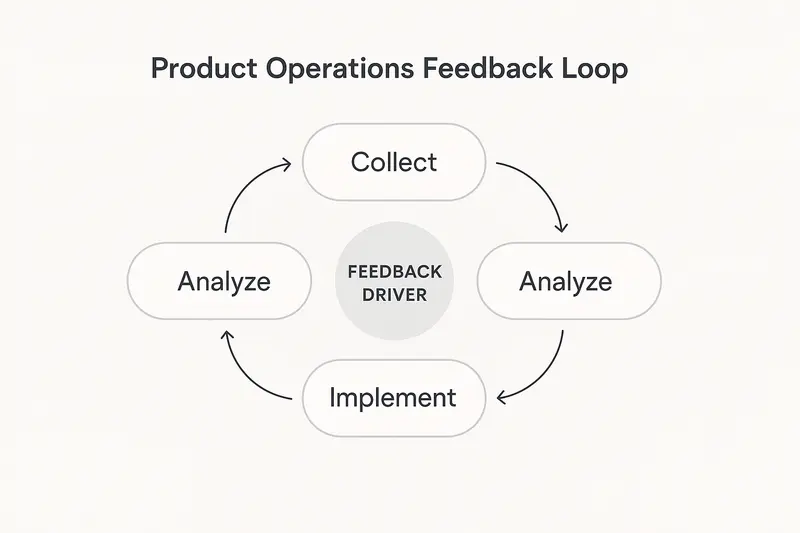
What makes a feedback loop bulletproof
Product operations sits at the center, orchestrating flow and quality. It connects support, sales, product, and engineering so feedback reaches the right owner with the right context.
- Clear ownership, documented paths, and SLAs for response
- Frictionless intake, low effort to submit and log
- Consistent structure, one language for feedback and outcomes
- Tight integration with delivery tools
- Routine follow up with customers
If this structure breaks, feedback becomes a pile of text. When it works, the loop compounds value. See the framing on product ops as infrastructure in Mind the Product’s overview of feedback loops in product ops: https://www.mindtheproduct.com/how-to-build-a-bulletproof-feedback-loop-in-product-ops/
Build the loop in four stages
A loop that survives scale is predictable. We design four stages and make each one boring in the best way: stable, repeatable, auditable.
1) Collect: create a feedback river
The system should push high quality feedback to teams, not the other way around. Centralize all inputs and make capture effortless.
- Channels: in‑app widgets, support tickets, sales notes, interviews, NPS, analytics
- Low friction: a click, a reaction, or a short form, not a long essay
- Structure: tags for product area, user segment, severity, and opportunity type
- Evidence: screenshots, logs, and direct quotes
Birdie’s concept of a feedback river captures this well: https://birdie.ai/blog/feedback-river-product-ops-priority/
Practical guardrails we use:
- Reject items without a clear user problem statement
- Auto attach account tier and ARR where possible
- Batch import daily from support and CRM to avoid manual drift
2) Analyze: turn noise into insight
Use human judgment supported by AI. Cluster by problem, segment by persona, and score by impact.
- Combine qualitative quotes with product usage to verify patterns
- Tag by problem themes, not only feature ideas
- Segment by plan, role, region, device
- Time series views to spot rising issues before they burn
Keep the process lean. AI can auto‑categorize and surface sentiment so analysts focus on meaning, not sorting.
3) Implement: tie insight to delivery
Insights should map directly to tickets, RFCs, or experiments. No orphaned docs.
- Link feedback IDs to epics and PRDs
- Set “definition of done” to include customer impact hypothesis
- Track a simple SLA: idea to shipped increment in days
Feature flag platforms make safe rollout possible as you test feedback‑driven changes with a subset of users. See LaunchDarkly’s take on closing the loop with experimentation: https://launchdarkly.com/blog/product-feedback-loop/
4) Follow up: close the loop
Notify contributors when you ship, and ask for a quick check on outcome. A short, specific note builds trust.
- What changed, why it matters, and a link to try it
- Invite a 30‑second rating on whether the change solved the problem
- Re‑tag the original feedback as resolved or needs‑more‑work
Strategic implementation framework
Getting this right is less about tools, more about choreography. We roll it out in phases.
Set objectives and success criteria
Decide what you are trying to move: CSAT, feedback‑to‑feature velocity, retention, or support cost. Productboard’s guide on organizing feedback ties objectives to process choices: https://www.productboard.com/blog/how-to-organize-customer-feedback/
Define a small set of targets, for example:
- Reduce average time from validated insight to shipped improvement to 45 days
- Close the loop with 80 percent of reporters within 7 days of a release
- Cut duplicate feedback by 30 percent with better tagging
Design simple, auditable workflows
Document intake, triage, scoring, and handoff. Assign owners for each step. Keep forms short. Standardize tags. Make it easy to pull a weekly report without heroics.
Pilot, then scale
Start with one product area for 60 days. Measure throughput, quality, and stakeholder satisfaction. Fix the rough edges, then roll out org‑wide.
Mature the system
Review quarterly. Eliminate vanity metrics. Tune thresholds. Refresh examples and training. Treat the loop itself as a product that you iterate.
Tools and integrations that keep the river flowing
Great tools make the loop faster, but they should feel invisible.
- Intake: in‑app micro‑prompts, interview notes, support sync
- Central hub: a single place to collect, de‑duplicate, tag, and discuss
- Analysis: AI‑assisted clustering, sentiment, and segment views
- Delivery: two‑way links with Jira, Linear, or GitHub
- Comms: templates for release notes and customer updates
If you need a central hub that unifies intake, analysis, and customer updates, see Sleekplan’s feature set: https://sleekplan.com/features/
Culture and habits over dashboards
Process collapses without culture. Leaders should ask for customer voice in every roadmap review. Product ops should reduce the typing tax on PMs and keep them in front of customers, not spreadsheets.
A practical cadence we use:
- Weekly, 30‑minute triage with product, support, and engineering
- Biweekly analysis review, top 5 themes with segments and quotes
- Monthly roadmap sync, feedback‑to‑feature links and status
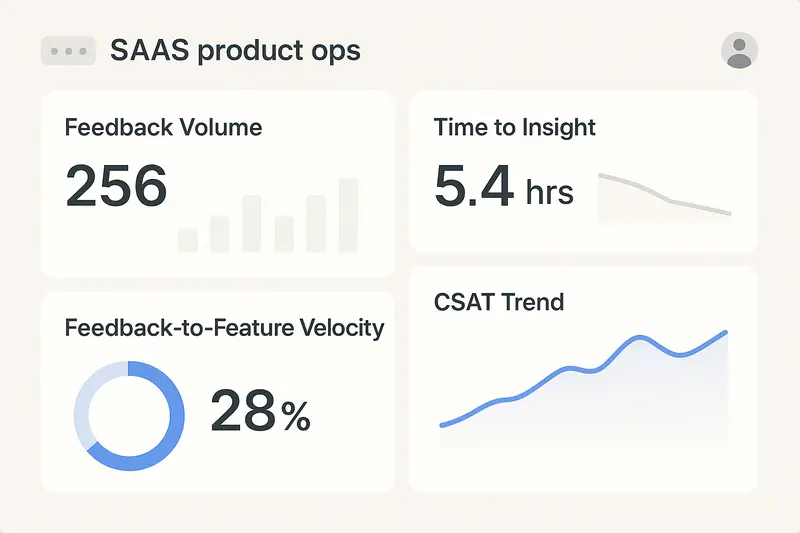
Metrics that actually move behavior
Measure what shows momentum, not just motion.
- Volume and velocity: submissions per week, time to triage, time to insight
- Feedback‑to‑feature velocity: average days from first validated signal to shipped change
- CSAT trend: before and after a release, segmented by plan
- Adoption and retention: feature adoption within 14 days, churn risk movement
- Internal quality: percent of items with complete tags, orphaned insights, rework
Mind the Product outlines how structured loops cut waste and improve satisfaction: https://www.mindtheproduct.com/how-to-build-a-bulletproof-feedback-loop-in-product-ops/
Advanced moves when you hit scale
- Predictive analysis: forecast rising themes from sentiment and volume
- Segment depth: weight inputs by ARR, persona, lifecycle stage
- Experimentation: ship behind flags, compare outcomes across cohorts
- Strategic signals: link feedback to pricing, packaging, and positioning decisions
Quick FAQ
-
What is a product operations feedback loop? A system that continuously collects, analyzes, implements, and follows up on customer feedback so product decisions reflect real user needs.
-
How do I prioritize feedback without bias? Score by customer impact, effort, and strategic fit. Add segment weight. Review the top picks with a cross‑functional group.
-
How fast should a good loop run? Healthy teams triage within 72 hours, validate within 2 weeks, and ship a first improvement within 30 to 60 days.
-
Do we need AI for analysis? You can start without it, but AI helps with clustering and sentiment when volume climbs. Humans still decide what matters.
Common pitfalls to avoid
- Treating feature requests as requirements instead of probing the underlying problem
- Collecting feedback without context, then guessing later
- Keeping analysis in slides with no links to delivery
- Forgetting to follow up with customers who raised the issue
A practical 30‑60‑90 day rollout
- Days 1–30: choose objectives, define tags, wire up intake, run weekly triage
- Days 31–60: add AI‑assisted analysis, link insights to delivery, start follow ups
- Days 61–90: publish metrics, expand to more teams, refine templates and SLAs
Final note
We have seen teams cut duplicate requests by a third in one quarter, raise CSAT by 8 points, and halve time to a meaningful fix. The common thread is craft, not shortcuts. Build the river, keep it flowing, and keep talking to customers.